Makine öğrenmesi, bilgisayar sistemlerine açık açık tüm kuralları yazmadan, veriden örüntü öğrenme yeteneği kazandıran mühendislik disiplinidir. Bu tanım ilk bakışta kısa görünse de etkisi son derece büyüktür; çünkü günümüzde öneri sistemlerinden üretim hatlarındaki kalite denetimine, tıbbi görüntü analizinden dil modellerine kadar uzanan çok geniş bir alanı aynı çatı altında toplar. Makine öğrenmesini anlamak isteyen herkes için en kritik adım, büyük ve karmaşık modellerden önce küçük fakat prensipleri çıplak biçimde gösteren modelleri iyi kavramaktır. Perceptron bu yüzden hâlâ merkezî bir öğretim aracıdır.
Perceptron, modern yapay sinir ağlarının atası olarak görülen, doğrusal karar verme mantığını son derece şeffaf şekilde sunan bir modeldir. Bugün devasa çok katmanlı ağlardan, transformer tabanlı sistemlerden ve milyarlarca parametreli modellerden söz ediyor olabiliriz; fakat bu büyük sistemlerin içinde çalışan birçok nöronun temel mantığı, hâlâ perceptron düşüncesinin genişletilmiş bir versiyonudur. Bu nedenle perceptron yalnızca tarihsel bir merak konusu değildir; aksine model tasarımı, karar sınırı, ağırlık güncelleme, hata sinyali ve temsil gücü gibi temel kavramları anlamak için en temiz giriş kapılarından biridir.
Bu kapsamlı rehberde makine öğrenmesinin ne olduğunu, hangi öğrenme rejimlerine ayrıldığını, perceptronun matematiksel yapısını, nasıl eğitildiğini, neden lineer ayrılabilirlik kavramıyla birlikte düşünülmesi gerektiğini ve neden XOR gibi problemler karşısında sınırına ulaştığını ayrıntılı biçimde ele alacağız. Ayrıca perceptron ile lojistik regresyon, destek vektör makineleri ve çok katmanlı perceptron arasındaki farkları açıklayacak; gerçek dünyadaki kullanım senaryolarını, model seçimi açısından hangi durumda işe yarayıp hangi durumda yetersiz kaldığını da net bir çerçeve içinde inceleyeceğiz.
Perceptron küçük bir model olabilir; ancak karar sınırının nasıl oluştuğunu, öğrenmenin hataya nasıl tepki verdiğini ve sinir ağlarının neden katmanlaşmak zorunda kaldığını anlamak için eşsiz bir laboratuvardır.
Bu yazıda neler bulacaksınız?
- Makine öğrenmesinin profesyonel fakat anlaşılır bir temel tanımı
- Perceptronun tarihçesi, matematiği ve eğitim kuralı
- Lineer ayrılabilirlik, karar sınırı ve XOR probleminin anlamı
- Perceptron ile lojistik regresyon, SVM ve MLP karşılaştırması
- Sıfırdan bir perceptron implementasyonu ve pratik model seçimi rehberi
Makine Öğrenmesi Nedir?
Makine öğrenmesi en yalın hâliyle, veriden fonksiyon öğrenme problemidir. Elinizde örnekler vardır: bazı girdiler ve bu girdilere karşılık gelen çıktılar, kimi zaman da yalnızca girdilerin kendileri. Amaç, bu örneklerden hareketle gelecekte göreceğiniz yeni veriler üzerinde makul tahmin yapabilecek bir kural ailesi inşa etmektir. Bu kural aileleri bazen basit doğrusal modeller, bazen karar ağaçları, bazen de çok katmanlı sinir ağları olabilir. Fakat ortak tema şudur: sistem, insanın tek tek yazdığı if-else bloklarından değil, veriden çıkarılan örüntülerden güç alır.
Burada kritik kelime genellemedir. Makine öğrenmesi sadece eğitim verisini ezberlemek için kullanılmaz; esas değer, daha önce hiç görülmemiş örnekler karşısında da işe yarayan bir karar mekanizması üretmesidir. İyi bir model, eğitim setindeki kalıpları rastgele gürültüyle karıştırmadan öğrenebilmelidir. Bu nedenle makine öğrenmesi pratiğinde veri kalitesi, özellik seçimi, model karmaşıklığı, düzenlileştirme, doğrulama stratejisi ve hata metrikleri merkezi rol oynar. Modelin öğrendiği şey gerçek bir örüntü mü, yoksa yalnızca eğitildiği veri setine özgü bir tesadüf mü sorusu, bu alanın omurgasını oluşturur.
Mühendislik perspektifinden bakıldığında makine öğrenmesi bir otomasyon teknolojisidir, fakat sıradan bir otomasyon değildir. Klasik yazılımda kurallar önceden tanımlanır; makine öğrenmesinde ise kuralın parametreleri veriyle uyarlanır. Örneğin sahte e-posta tespiti yapmak için bütün spam kalıplarını tek tek kodlamak yerine, çok sayıda etiketli e-posta örneği üzerinden bir sınıflandırıcı eğitirsiniz. Sistem hangi kelimelerin, hangi dizilimlerin, hangi istatistiksel desenlerin spam olasılığını yükselttiğini kendi içinde öğrenir. Bu, yazılım geliştirmeyi kuralları yazmaktan davranışı şekillendirmeye doğru dönüştürür.
Makine öğrenmesinin değer üretmesi için büyük model kullanmak zorunda değilsiniz. Çoğu iş problemi için temel soru şudur: kararınızı hangi veri üzerinden, ne kadar açıklanabilir bir biçimde ve ne kadar operasyonel maliyetle vermek istiyorsunuz? Bazı problemler küçük doğrusal modellerle son derece iyi çözülür; bazıları ise karmaşık, doğrusal olmayan temsiller gerektirir. Perceptron bu ayrımın tam kalbinde yer alır. Çünkü bir yandan karar vermenin özünü yalın biçimde gösterir, diğer yandan da bu yalınlığın nereye kadar işe yaradığını anlamanızı sağlar.
Makine Öğrenmesinin Temel Öğrenme Türleri
Makine öğrenmesinin alt türlerini anlamak, perceptronun doğru bağlama yerleşmesi için önemlidir. Perceptron tipik olarak denetimli öğrenme altında incelenir; çünkü model, etiketli örnekler üzerinden doğru sınıfı tahmin etmeyi öğrenir. Girdileriniz vardır ve her girdi için hedef sınıf bilinir. Model, hatalı sınıflandırma yaptığında ağırlıklarını günceller. Bu yapı, sınıflandırma problemlerinin büyük bir bölümünde karşımıza çıkan temel şablondur.
Denetimsiz öğrenmede ise işler farklıdır. Burada modelin önünde doğru cevap anahtarı bulunmaz. Verinin doğal kümelenmesini, sık tekrar eden örüntülerini veya daha düşük boyutlu temsillerini bulmaya çalışırsınız. Müşteri segmentasyonu, anomali tespiti veya boyut indirgeme bunun klasik örnekleridir. Perceptron doğrudan bu sınıfta yer almaz; çünkü perceptronun öğrenme kuralı, hata sinyaline dayalıdır ve hata sinyalinin oluşması için etiket gerekir.
Kendi kendine öğrenme ve pekiştirmeli öğrenme gibi daha ileri rejimler, modern yapay zekânın ana akımında çok görünür hâle gelmiştir. Büyük dil modelleri, aslında çok geniş ölçekli bir temsil öğrenme paradigmasından güç alır. Fakat bu büyük sistemlerde bile temel sorun aynıdır: hangi girdiyi nasıl temsil edeceksiniz, hangi parametreler neyi ağırlıklandıracak, karar sınırı ya da karar dağılımı nasıl şekillenecek? Dolayısıyla perceptron, tüm modern akımların temelinde duran ağırlıklı doğrusal birleşim fikrini görünür kılan çekirdek bir örnektir.
Perceptron Nedir ve Neden Hâlâ Önemlidir?
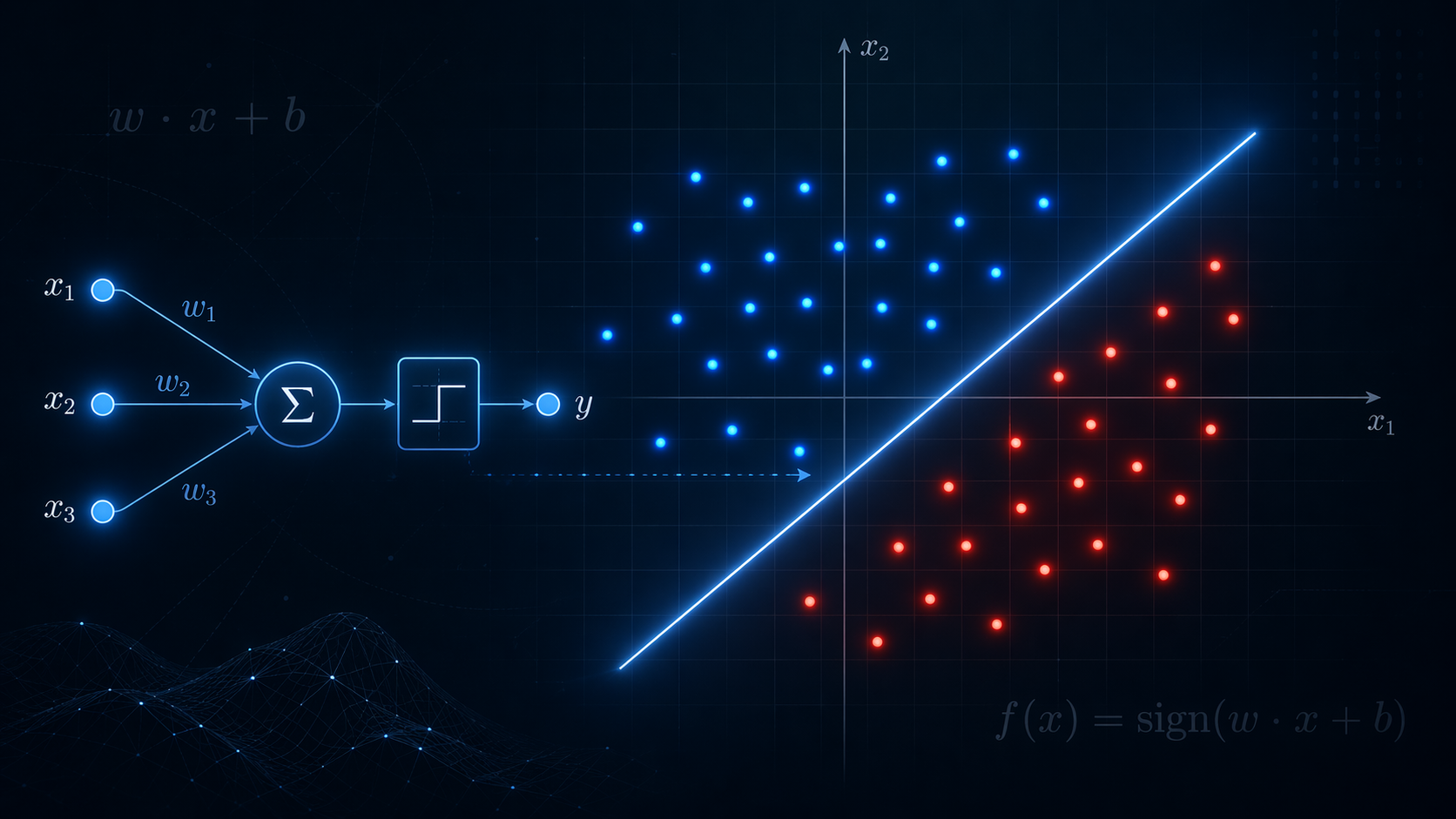
Perceptron, Frank Rosenblatt tarafından 1957 yılında ortaya konan, biyolojik nöronlardan esinlenen doğrusal bir sınıflandırıcıdır. Modelin mantığı son derece yalındır: Her girdi özelliğine bir ağırlık verilir, bu ağırlıklarla girdiler çarpılıp toplanır, sonra bias eklenir ve sonuç bir eşik fonksiyonundan geçirilerek çıktı sınıfı elde edilir. Başka bir deyişle perceptron, veriyi uzayda doğrusal bir yüzeyle ayırmaya çalışan bir karar makinesidir.
Bugün perceptronun tek başına kullanıldığı alanlar sınırlı olabilir; çünkü daha esnek modeller birçok problemde daha yüksek performans sunar. Ancak perceptronun pedagojik değeri olağanüstüdür. Çünkü çoğu modern modelin içine gömülü olan mantığı, dikkat dağıtan karmaşıklıklar olmadan gösterir. Örneğin çok katmanlı sinir ağlarında her nöron, belirli bir ağırlıklı toplam ve aktivasyon süreci işletir. Perceptron bu akışın en sade hâlidir. Dolayısıyla perceptronu anlamak, derin öğrenmeye geçiş için kavramsal bir köprü görevi görür.
Perceptronun önemini artıran bir başka yön de yorumlanabilirliğidir. Ağırlıkların büyüklüğü ve işareti, belirli özelliklerin kararı hangi yönde etkilediğini sezgisel olarak anlamanıza yardım eder. Elbette yüksek boyutlu veri setlerinde bu yorum her zaman kolay olmayabilir; ancak yine de perceptron, kara kutu davranışı düşük olan modellerden biridir. Bu özellik, eğitim ve model analizi açısından önemli bir avantajdır.
Ayrıca perceptron, öğrenme kurallarının doğasını düşünmek için çok iyi bir araçtır. Modelin yaptığı şey, hatalı örnekler geldiğinde karar sınırını onları doğru tarafa itecek yönde güncellemektir. Bu, öğrenmeyi soyut bir optimizasyon problemi olmaktan çıkarıp geometrik bir hareket olarak düşünmenizi sağlar. Karar yüzeyi, her hata ile biraz daha yeniden konumlanır. Bu sezgi, optimizasyon, gradient descent ve daha karmaşık hata geri yayılımı yöntemlerini anlamayı da kolaylaştırır.
Perceptron'un Matematiksel Yapısı
Perceptronun matematiksel yapısını anlamak için önce girdileri vektör biçiminde düşünmek gerekir. Elinizde x = [x1, x2, ..., xn] biçiminde bir özellik vektörü olsun. Her özelliğe karşılık bir ağırlık bulunur: w = [w1, w2, ..., wn]. Model önce bu iki vektörün iç çarpımını alır; yani her özelliği kendi ağırlığıyla çarpar ve hepsini toplar. Ardından b bias terimini ekler. Böylece z = w · x + b skoru elde edilir. Bu skor, modelin örneği hangi sınıfa daha yakın gördüğünü ifade eder.
Klasik perceptronda aktivasyon fonksiyonu çoğunlukla adım fonksiyonudur. Eğer z skoru belirlenen eşikten büyükse çıktı bir sınıfa, değilse diğer sınıfa atanır. İkili sınıflandırma için bu çıktı 0 ve 1 ya da -1 ve +1 şeklinde kodlanabilir. Buradaki ana fikir, modelin sürekli bir skor üretmesi ve sonra bu skoru ayrık bir karara çevirmesidir. Bu nedenle perceptron, olasılık üretmekten ziyade karar vermeye odaklanan bir mekanizma olarak düşünülebilir.
Geometrik açıdan bakıldığında w · x + b = 0 denklemi, özellik uzayında bir hiper düzlemi temsil eder. İki boyutta bu bir doğru, üç boyutta bir düzlem, daha yüksek boyutlarda ise hiper düzlem olarak yorumlanır. Perceptronun yaptığı iş, veriyi bu yüzeyin iki tarafına ayırmaktır. Ağırlık vektörü, yüzeyin yönünü belirler; bias ise bu yüzeyin uzay içindeki konumunu kaydırır. Dolayısıyla eğitim süreci, aslında bu hiper düzlemin doğru yerde ve doğru açıda konumlanmasını öğrenmektir.
Bu yapı aynı zamanda öz nitelik mühendisliğinin neden önemli olduğunu da açıklar. Eğer veriyi modele sunduğunuz koordinat sistemi, problemin doğal ayrımını görünür kılmıyorsa perceptron başarısız olabilir. Fakat uygun özellik dönüşümleri yaparsanız, daha önce ayrılmayan veri lineer olarak ayrılabilir hâle gelebilir. Bu yüzden model gücü ile temsil gücü birbirinden bağımsız değildir; çoğu zaman veriyi nasıl temsil ettiğiniz, hangi modeli kullandığınız kadar önemlidir.
Bu birkaç satırlık mantık, makine öğrenmesi tarihinde son derece önemli bir kırılma yaratmıştır. Çünkü sınıflandırma artık el yazımı kurallarla değil, veriye göre ayarlanan parametrelerle yapılmaktadır.
Perceptron Nasıl Eğitilir?
Perceptron eğitiminin özü, yanlış sınıflandırılmış örnekleri düzeltmektir. Model bir örneği yanlış tarafa attığında, ağırlıklar ve bias bu hatayı azaltacak yönde güncellenir. Eğer hedef etiketi y ve mevcut örnek x ise, klasik perceptron güncellemesi kabaca w = w + η · y · x ve b = b + η · y şeklinde yazılabilir. Buradaki η öğrenme oranıdır; yani güncellemenin ne kadar büyük adımlarla yapılacağını belirler. Bu kural, hatalı örneği doğru sınıfa doğru itmeye yarar.
Sezgisel olarak düşünürseniz modelin her hata karşısında şunu söylediğini varsayabilirsiniz: Bu örneği yanlış tarafa koymuşum, demek ki bu örneğin sahip olduğu özelliklerin karar üzerindeki etkisini biraz artırmalı ya da azaltmalıyım. Eğer pozitif olması gereken bir örnek negatif tarafa düşmüşse, onu temsil eden özelliklerin ilgili ağırlıkları yükseltilir. Tersi durumda düşürülür. Bu çok yalın güncelleme mantığı, daha sonra gradient descent ve backpropagation gibi çok daha güçlü optimizasyon tekniklerinin sezgisel çekirdeğine dönüşür.
Perceptron eğitimi genellikle veri seti üzerinde tekrar tekrar geçerek yapılır. Her tam geçişe epoch denir. Model bazı örnekleri başta yanlış sınıflandırır, sonra ağırlıklar değiştikçe karar sınırı hareket eder ve hata sayısı azalır. Eğer veri gerçekten lineer ayrılabiliyorsa, perceptron yakınsama teoremi bize modelin sonlu sayıda güncelleme ile bir çözüm bulabileceğini söyler. Bu, perceptronun teorik açıdan en önemli sonuçlarından biridir.
Ancak veri lineer ayrılabilir değilse süreç karmaşıklaşır. Model bir noktada takılabilir, sürekli hatalar yapabilir ya da belirli bir salınım içinde kalabilir. İşte bu, model seçiminin problem yapısıyla neden bu kadar yakından ilişkili olduğunu gösterir. Her algoritmanın kendine uygun bir problem geometrisi vardır. Perceptronun gücü, lineer ayrım gerektiren, hızlı ve basit kararların yeterli olduğu sahalarda ortaya çıkar; fakat veri yapısı daha karmaşıksa farklı araçlara ihtiyaç duyarsınız.
Burada kullanılan etiket kodlaması -1 ve +1 olduğunda matematiksel yorum daha da berraklaşır. Hatalı örnek, karar sınırını kendi lehine itecek yönde güncelleme üretir.
Lineer Ayrılabilirlik Nedir?
Lineer ayrılabilirlik, iki sınıfın özellik uzayında tek bir doğru, düzlem ya da genel anlamıyla hiper düzlem ile kusursuz biçimde ayrılabilmesi demektir. Bu kavram perceptronun merkezindedir; çünkü perceptron özü itibarıyla doğrusal bir karar vericidir. Eğer veriniz böyle bir yüzey ile ayrılabiliyorsa perceptron oldukça anlamlı ve etkili olabilir. Eğer ayrılamıyorsa modelin yapısal kapasitesi yetersiz kalır. Bu, eğitim verisinin az olmasından ya da hiperparametrelerin kötü seçilmesinden bağımsız bir kapasite sınırıdır.
İki boyutlu basit bir örnek düşünelim: kırmızı noktalar sol üst bölgede, mavi noktalar sağ alt bölgede toplanmış olsun. Tek bir doğru çekerek bu iki grubu ayırabilirsiniz. Böyle bir durumda perceptron, yeterli sayıda geçişten sonra doğruyu uygun konuma getirebilir. Fakat noktalar çapraz biçimde dizilmişse, yani XOR benzeri bir örüntü varsa tek doğru yetersiz kalır. Siz doğruyu ne kadar döndürürseniz döndürün, mutlaka yanlış tarafta kalan örnekler olacaktır.
Bu kavramın mühendislik açısından çok önemli bir dersi vardır: Bazen asıl problem modelde değil, temsilde yatar. Ham özellik uzayında lineer ayrılmayan veri, uygun bir dönüşümden sonra ayrılabilir hâle gelebilir. Kernel yöntemleri, özellik eşlemeleri ve çok katmanlı ağların iç temsilleri tam da bu nedenle güçlüdür. Perceptron burada bize şunu öğretir: her öğrenme problemi, veriyi hangi uzayda gördüğünüze bağlıdır. Karar sınırı yalnızca model parametrelerinin değil, veri temsilinin de ürünüdür.
Perceptron'un Güçlü Yanları ve Sınırları
Perceptronun en güçlü yanı sadeliğidir. Çok az parametreyle çalışır, eğitim mantığı kolay anlaşılır ve bazı veri akış senaryolarında çevrim içi güncellemeye doğal biçimde uygundur. Yorumlanabilirlik açısından da avantajlıdır; çünkü hangi özelliğin kararı hangi yönde etkilediğini anlamak, karmaşık derin modeller kadar zor değildir. Bu özellikler perceptronu özellikle eğitim, temel prototipleme ve doğrusal karar ihtiyacı olan hafif uygulamalar için değerli kılar.
İkinci önemli avantaj hızdır. Küçük ve orta ölçekli doğrusal problemler için perceptron son derece hafif bir çözüm olabilir. Bellek ihtiyacı düşük, implementasyonu kolay ve operasyonel maliyeti sınırlıdır. Bazen makine öğrenmesi projelerinde en iyi model en karmaşık olan değil, en hızlı devreye alınabilen ve en rahat denetlenebilen modeldir. Perceptron bu bakımdan yalınlığın gücünü hatırlatır.
Bununla birlikte perceptronun temel sınırı da aynı sadelikten gelir. Model doğrusal değildir; dolayısıyla lineer olmayan örüntüleri tek başına öğrenemez. Olasılık kalibrasyonu doğal olarak üretmez, gürültülü verilerde kararsız davranabilir ve karmaşık sınırlar gerektiğinde yetersiz kalır. Ayrıca modern uygulamaların çoğunda veri, tek bir hiper düzlemle ayrılabilecek kadar basit değildir. Bu nedenle perceptron günümüzde çoğu zaman son çözümden çok, daha karmaşık çözümlerin öncül kavramsal aracı olarak kullanılır.
Perceptronun pratik avantajları
- Basit ve hızlıdır; özellikle doğrusal sınıflandırma için maliyeti düşüktür.
- Karar sınırı ve ağırlık güncellemesi sezgisel biçimde yorumlanabilir.
- Çevrim içi öğrenme mantığına uygundur; yeni örnek geldikçe güncellenebilir.
- Derin öğrenmeye geçmeden önce temel kavramları öğretmek için idealdir.
Perceptronun doğal sınırlamaları
- Lineer olmayan örüntülerde yapısal kapasitesi yetmez.
- Klasik formu olasılık üretmez; daha sert bir karar davranışı gösterir.
- Özellik mühendisliğine ve veri temsilinin kalitesine duyarlıdır.
- Gürültülü veya çakışan sınıf yapılarında kararlı çözüm üretmek zorlaşabilir.
XOR Problemi Neden Tarihî Bir Kırılmadır?
XOR problemi, yapay zekâ tarihindeki en sembolik örneklerden biridir. Çünkü XOR çıktısı, girdilerin aynı olup olmamasına göre belirlenir ve bu örüntü tek bir doğru ile ayrıştırılamaz. Bir başka deyişle, iki girişli XOR veri noktaları düzlemde çapraz konumlandığında, hangi doğruyu çizerseniz çizin iki sınıfı kusursuz ayıramazsınız. Bu örnek, tek katmanlı perceptronun sınırını son derece yalın ve görsel biçimde ortaya koyar.
Bu sınırlama uzun süre sinir ağları araştırmalarına yönelik şüphelerin artmasına yol açmıştır. Çünkü eğer model bu kadar temel bir mantıksal işlemi dahi öğrenemiyorsa, daha karmaşık dünyaları nasıl temsil edecektir sorusu gündeme gelmiştir. Ancak asıl cevap perceptronun yanlış olduğunda değil, tek katmanlı olduğunda saklıdır. Birden fazla katman ve doğrusal olmayan aktivasyonlar devreye girdiğinde, model artık doğrusal olmayan karar yüzeyleri öğrenebilir hâle gelir.
Dolayısıyla XOR problemi bir başarısızlık hikâyesi değil, kapasite analizi dersidir. Modelin neyi yapamadığını bilmek, neyi yapabileceğini bilmek kadar önemlidir. Modern derin öğrenme, büyük ölçüde bu kapasite engellerini aşmak için geliştirilen mimari ve optimizasyon yaklaşımlarının toplamıdır. Perceptron burada kavramsal pusula görevi görür: tek katmanla hangi geometrik yapı mümkün, çok katmanla hangi yeni temsil gücü açılıyor sorularının başlangıç noktasıdır.
Bugün transformer, diffusion veya çok büyük dil modellerinden söz ederken bile aslında temsil gücü tartışmasının daha ileri sürümlerini yapıyoruz. Katman sayısı, doğrusal olmayanlık, dikkat mekanizması ve veri ölçeği arttıkça modelin öğrenebileceği yapı ailesi büyüyor. XOR örneği bize şunu hatırlatır: kapasite artışı keyfi bir lüks değildir; problem geometrisinin gerektirdiği bir zorunluluktur.
Tek Katmanlı Perceptron ile Çok Katmanlı Perceptron Arasındaki Fark
Tek katmanlı perceptron, girdiden doğrudan çıktıya giden tek bir karar yüzeyi kurar. Bu yüzden kapasitesi doğrusal sınıflandırma ile sınırlıdır. Çok katmanlı perceptron ise araya gizli katmanlar ekler. Her gizli katman, girdiyi yeni bir temsil uzayına taşır. Bu yeni temsil uzayında başlangıçta doğrusal olmayan görünen bir problem, sonraki katmanda daha kolay ayrılabilir hâle gelebilir. İşte sinir ağlarını güçlü yapan şey yalnızca çok parametreye sahip olmaları değil, temsili katman katman dönüştürmeleridir.
Çok katmanlı yapının etkin olması için diferansiyellenebilir aktivasyonlar ve hata geri yayılımı gerekir. Klasik eşik fonksiyonu, türev tabanlı optimizasyon için elverişli değildir. Bu nedenle sigmoidal, tanh, ReLU ve türevlenebilir başka aktivasyonların kullanımı kritik hâle gelmiştir. Bu geçiş, perceptrondan modern sinir ağlarına doğru yapılan en önemli mühendislik sıçramalarından biridir. Artık model yalnızca bir karar sınırı öğrenmez; birçok ara temsili birlikte optimize eder.
Bununla birlikte çok katmanlı ağlara geçiş, yorumlanabilirliğin azalması ve eğitim maliyetinin artması gibi yeni sorunları da beraberinde getirir. Bu nedenle her problem için otomatik olarak daha derin ağ seçmek doğru değildir. Eğer problem basit, veri miktarı sınırlı ve açıklanabilirlik kritik ise daha yalın modeller hâlâ rasyonel olabilir. Yani perceptron sadece bir başlangıç modeli değil, aynı zamanda model karmaşıklığının ne zaman gerçekten gerekli olduğunu sorgulatan bir referans noktasıdır.
Perceptron, Lojistik Regresyon, SVM ve MLP Karşılaştırması
Perceptron ile lojistik regresyon sıklıkla karıştırılır; çünkü ikisi de doğrusal karar yüzeyi üretir. Fakat aralarında kritik farklar vardır. Perceptron hatalı örnekler geldiğinde ağırlıkları güncelleyen daha sezgisel bir karar kuralı kullanır. Lojistik regresyon ise olasılık yorumu sunar ve kayıp fonksiyonunu optimize ederek öğrenir. Eğer kararın ne kadar emin olduğunu ifade etmek istiyorsanız lojistik regresyon çoğu zaman daha uygun bir seçimdir.
SVM ise marj kavramı üzerinden düşünür; amaç yalnızca ayırmak değil, mümkün olan en güvenli ayırımı yapmaktır. Özellikle uygun kernel seçildiğinde doğrusal olmayan yapılarda da güçlü olabilir. Ancak ölçek ve ayar yönetimi açısından her zaman en pratik çözüm olmayabilir. Perceptron burada daha hafif ve anlaşılır bir alternatif olarak kalır, fakat temsil gücü daha düşüktür.
Çok katmanlı perceptron ise doğrusal olmayan aktivasyonlar sayesinde çok daha zengin karar yüzeyleri öğrenebilir. Bu da onu karmaşık problemler için daha güçlü kılar. Ancak veri ihtiyacı, eğitim süresi, aşırı uyum riski ve hiperparametre karmaşıklığı artar. Dolayısıyla model seçimi yalnızca doğruluk skoruna bakılarak yapılmamalıdır; verinin boyutu, gürültü seviyesi, açıklanabilirlik ihtiyacı, operasyon maliyeti ve bakım yükü birlikte değerlendirilmelidir.
Sıfırdan Bir Perceptron Nasıl Kodlanır?
Perceptronun gücü, matematiği kadar implementasyonunun da yalın olmasından gelir. Aşağıdaki örnek, Python ile basit bir perceptron sınıfının nasıl kurulabileceğini gösterir. Bu örnek eğitimsel amaç taşır; yani modern üretim sistemlerinde doğrudan bu kadar çıplak bir sürüm kullanmayabilirsiniz. Buna rağmen modelin ne yaptığını katman katman görmenin en iyi yollarından biri, onu birkaç onlarca satırla kendiniz yazmaktır.
Kodun mantığı şu şekildedir: ağırlıkları başlangıçta sıfır ya da küçük rastgele değerlerle kurarsınız, veri üzerinde epoch epoch dolaşırsınız, her örnek için tahmin üretir ve hata varsa ağırlıkları güncellersiniz. Eğitim tamamlandığında yeni örnekler üzerinde predict çağrısı ile sınıf etiketi alırsınız. Bu iskelet, daha sonra lojistik regresyon, tek katmanlı sinir ağı ya da gradient descent tabanlı başka modelleri anlamayı da kolaylaştırır.
Bu örnekte OR mantık kapısı lineer ayrılabilir olduğu için perceptron rahat biçimde çözüme ulaşır. Aynı yapıyı XOR etiketiyle denediğinizde ise modelin başarısız olduğunu görürsünüz. Bu, teorik kapasite ile pratik davranışın aynı noktada buluştuğu çok değerli bir deneydir.
Dikkat edilirse burada update değeri, hedef ile tahmin arasındaki fark üzerinden kurulmuştur. Bu, eğitimsel açıdan anlaşılır bir varyanttır. Daha klasik yazımlarda etiketler -1 ve +1 biçiminde kodlanarak güncelleme buna göre ifade edilir. Her iki durumda da ana fikir aynıdır: hata varsa ağırlıkları düzelt, yoksa olduğu gibi bırak.
Gerçek Dünyada Perceptron Nerede Kullanılır?
Günümüzün büyük ölçekli ticari sistemlerinde perceptron çoğu zaman tek başına nihai model olarak kullanılmaz; ancak düşük maliyetli, hızlı ve basit karar ihtiyacı olan ortamlarda hâlâ işe yarayabilir. Örneğin küçük sensör sistemlerinde, sınırlı özellik sayısı olan akış verilerinde veya doğrusal ayrımın yeterli olduğu filtreleme görevlerinde perceptron mantığı uygulanabilir. Özellikle gömülü sistemler ve çevrim içi güncelleme gerektiren hafif sınıflandırma senaryoları buna uygundur.
Bunun yanında perceptronun asıl yaygın kullanımı dolaylıdır. Eğitim programlarında, veri bilimi bootcamp'lerinde, üniversite derslerinde ve araştırma odaklı temel eğitimlerde perceptron; optimizasyon, karar sınırı ve sinir ağı mantığını anlatmak için başvurulan ilk modellerden biridir. Çünkü lineer cebir, geometrik sezgi ve algoritmik öğrenme fikri burada temiz biçimde birleşir. Makine öğrenmesi düşüncesini sisli anlatılardan kurtarıp görünür hâle getirir.
Ayrıca pratik model seçimi açısından da perceptron, bir referans baseline olarak değerlidir. Yeni bir problemde çok karmaşık modellere geçmeden önce lineer bir çözümün nereye kadar işe yaradığını görmek akıllıca olabilir. Eğer basit bir perceptron ya da lojistik regresyon bile makul sonuç veriyorsa, daha pahalı modellerin sağlayacağı ek kazanç operasyonel maliyete değmeyebilir. Bu nedenle perceptron düşüncesi, yalnızca tarihsel bir konu değil, stratejik bir modelleme refleksidir.
Perceptron düşüncesinin pratikte yararlı olduğu senaryolar
- Hızlı bir baseline kurmak ve veri setinin lineer ayrım potansiyelini görmek istediğinizde
- Özellik mühendisliği sonrası karar sınırını sezgisel biçimde analiz etmek istediğinizde
- Gömülü ya da hesap gücü sınırlı sistemlerde çok hafif karar mekanizması aradığınızda
- Öğrencilere veya ekip arkadaşlarına sinir ağlarının temel mantığını anlatmak istediğinizde
Makine Öğrenmesi Projelerinde Model Seçimi İçin Pratik Çerçeve
Makine öğrenmesinde en sık yapılan hatalardan biri, problemi anlamadan model seçmeye çalışmaktır. Oysa doğru sıra genellikle tersidir: önce verinin yapısını, sınıf dağılımını, hata maliyetini, açıklanabilirlik ihtiyacını ve operasyonel kısıtları anlarsınız; sonra model ailesini seçersiniz. Perceptron bu süreçte çok yararlı bir düşünme aracıdır; çünkü size verinin lineer ayrılabilirlik derecesi hakkında hızlı bir fikir verir. Eğer temel doğrusal modeller başarısızsa, daha güçlü temsil mekanizmalarına geçmeniz gerektiğini erken fark edersiniz.
İkinci kritik nokta, başarı metriklerinin iş problemiyle uyumlu olmasıdır. Basit bir doğrusal model kimi zaman doğruluk açısından birkaç puan geride kalabilir, fakat bakım kolaylığı, açıklanabilirlik ve gecikme maliyeti açısından daha değerli olabilir. Finans, sağlık, üretim ve kamu gibi alanlarda modelin neden o kararı verdiğini açıklayabilmek çoğu zaman birkaç puanlık skor farkından daha önemlidir. Bu nedenle perceptron gibi basit modelleri tamamen eski veya yetersiz saymak mühendislik açısından yüzeysel bir yaklaşımdır.
Üçüncü nokta ise veri temsilidir. Perceptron kötü sonuç veriyorsa bu her zaman modelin yetersiz olduğu anlamına gelmez; bazen özellik uzayı zayıftır. Tersine, çok güçlü bir derin model iyi sonuç veriyorsa bunun nedeni yalnızca model kapasitesi değil, verinin doğru biçimde işlenmiş olması da olabilir. Dolayısıyla model seçimi ile özellik tasarımını birlikte düşünmek gerekir. Perceptron burada size şu sert ama değerli soruyu sorar: Gerçekten karmaşık bir modele mi ihtiyacım var, yoksa veriyi daha iyi temsil etmeye mi?
Model seçerken sorulması gereken kritik sorular
- Problem doğrusal karar sınırına yakın mı, yoksa açıkça doğrusal olmayan bir yapı mı sergiliyor?
- Olasılık çıktısı gerekiyor mu, yoksa sert sınıf kararı yeterli mi?
- Açıklanabilirlik, gecikme süresi ve bakım kolaylığı ne kadar önemli?
- Veri miktarı büyük ama etiket az mı, yoksa zengin ve temiz etiketli veri mi var?
- Özellik mühendisliği ile sorun basitleştirilebilir mi, yoksa temsil gücü yüksek modele mi ihtiyaç var?
Perceptron Öğrenirken Sık Yapılan Kavramsal Hatalar
Perceptron öğrenirken yapılan en yaygın hata, bu modeli küçük olduğu için önemsiz sanmaktır. Oysa birçok öğrenci ve hatta bazı uygulayıcılar, perceptronu hızlıca geçip doğrudan derin öğrenme kütüphanelerine atladığında kritik sezgileri kaçırır. Ağırlığın ne anlama geldiği, bias teriminin karar sınırını nasıl kaydırdığı, neden bazı problemlerin tek katmanla çözülemediği ve veri temsilinin niçin model kapasitesi kadar belirleyici olduğu netleşmeden daha büyük modellere geçmek, karmaşıklığı yalnızca büyütür. Perceptron burada basit bir oyuncak değil, kavramsal netleştirici görevi görür.
İkinci hata, perceptron başarısız olduğunda otomatik olarak veri biliminin de başarısız olduğunu düşünmektir. Aslında perceptronun başarısızlığı çoğu zaman çok kıymetli bir bilgi taşır. Bu bilgi, problemin doğrusal bir yüzeyle ifade edilmediğini ya da mevcut özellik uzayının zayıf olduğunu söyler. Yani başarısızlık bile rehberlik eder. İyi mühendislik, modelin düştüğü yerde teşhis üretmektir. Eğer perceptron veriyi ayıramıyorsa bir sonraki soru şudur: Daha iyi özellikler mi üretmeliyim, yoksa daha yüksek temsil gücüne sahip bir modele mi geçmeliyim?
Üçüncü hata ise perceptronu yalnızca tarihsel bir dipnot gibi okumaktır. Oysa üretim ortamlarında kullandığımız modern sistemlerin önemli bir bölümü, özünde lineer birleşim, aktivasyon ve optimizasyon mantığını sürdürür. Her ne kadar mimariler karmaşıklaşsa da temel soru değişmez: hangi sinyal hangi parametreyle ne kadar ağırlıklandırılacak? Bu yüzden perceptron bilgisi, sadece geçmişe bakmak değil, bugünün modellerini daha rasyonel değerlendirebilmek için de gereklidir. Özellikle model hata analizi yaparken, kararın hangi bileşenlerden beslendiğini düşünme alışkanlığı perceptron bakışından güç alır.
Pratik çalışmalarda dikkat edilmesi gereken noktalar
- Özellikleri çok farklı ölçeklerde bırakmak, ağırlık güncellemelerinin dengesini bozabilir; temel ölçekleme iyi bir başlangıçtır.
- Etiket gürültüsü yüksekse perceptronun karar sınırı kararsızlaşabilir; veri temizliği, model karmaşıklığından önce düşünülmelidir.
- Basit model iyi çalışıyorsa sırf daha modern göründüğü için daha ağır mimariye geçmek her zaman rasyonel değildir.
- Perceptron sonucu zayıfsa, bunu yalnızca skor düşüklüğü değil aynı zamanda problem geometrisine dair tanısal bir sinyal olarak yorumlayın.
Sık Sorulan Sorular
Perceptron ile yapay sinir ağı aynı şey midir?
Hayır. Perceptron, yapay sinir ağlarının en temel yapı taşı olarak görülebilir; fakat tek başına bütün sinir ağı fikrini temsil etmez. Tek katmanlı perceptron doğrusal bir karar vericidir. Modern sinir ağları ise çok sayıda nöron, çoklu katman, doğrusal olmayan aktivasyon ve hata geri yayılımı ile çok daha zengin temsil gücüne sahiptir.
Perceptron ile lojistik regresyon arasındaki en net fark nedir?
En net fark, öğrenme ve çıktı yorumundadır. Perceptron daha sert bir karar mekanizması ve hata odaklı güncelleme kullanır. Lojistik regresyon ise sigmoid tabanlı olasılık üretir ve diferansiyellenebilir bir kayıp fonksiyonunu optimize eder. Yani lojistik regresyon, istatistiksel yorum ve kalibrasyon açısından daha güçlüdür.
Perceptron neden XOR problemini çözemez?
Çünkü XOR lineer ayrılabilir değildir. Tek katmanlı perceptron yalnızca tek bir hiper düzlem öğrenebilir. XOR örüntüsündeki iki sınıf, tek bir doğru ile ayrılmadığı için model yapısal olarak yetersiz kalır. Bu sınır, çok katmanlı ağların neden gerekli olduğunu anlamak açısından son derece öğreticidir.
Perceptron günümüzde tamamen demode bir model midir?
Hayır. Nihai üretim modeli olarak kullanımı sınırlı olabilir; fakat öğretim, baseline kurma, hafif doğrusal sınıflandırma ve model seçimi refleksi geliştirme açısından hâlâ değerlidir. Ayrıca modern sinir ağlarının temel mantığını anlamak için perceptron bilgisi vazgeçilmezdir.
Perceptron regresyon problemi çözer mi?
Klasik perceptron esasen sınıflandırma için tasarlanmıştır. Sürekli değer tahmini gerektiren regresyon problemlerinde farklı model aileleri tercih edilir. Elbette ağırlıklı toplam fikri regresyon dünyasında da vardır; fakat perceptronun standart eşik tabanlı çıktı yapısı onu öncelikle sınıf kararı için uygun kılar.
Perceptronun başarısını artırmak için ne yapılabilir?
Önce veri temsilini iyileştirmek gerekir. Özellik ölçekleme, uygun dönüşümler, anlamlı yeni özellikler üretme ve gürültülü veriyi temizleme çoğu zaman modelin kendisini değiştirmekten daha büyük etki yaratır. Eğer buna rağmen ayrım doğrusal değilse, çok katmanlı yapılara ya da alternatif model ailelerine geçmek gerekir.
Makine öğrenmesine yeni başlayan biri perceptronu neden öğrenmeli?
Çünkü perceptron, makine öğrenmesinin birçok temel kavramını aynı çerçevede toplar: özellik vektörü, ağırlık, bias, karar sınırı, hata, güncelleme, yakınsama ve kapasite sınırı. Bu kavramlar anlaşıldığında daha karmaşık modelleri öğrenmek çok daha sistematik ve az sisli hâle gelir.
Sonuç
Makine öğrenmesi, veriden davranış öğrenme sanatıdır; perceptron ise bu sanatın en temiz giriş derslerinden biridir. Küçük, sade ve doğrusal bir model olmasına rağmen; karar vermenin matematiğini, öğrenmenin hataya tepkisini, veri temsilinin önemini ve model kapasitesinin sınırlarını olağanüstü berraklıkla gösterir. Bu yüzden perceptron yalnızca tarihsel bir not değil, güncel yapay zekâ okuryazarlığının temel taşlarından biridir.
Eğer makine öğrenmesini gerçekten anlamak istiyorsanız yalnızca büyük modellerin sonuçlarına değil, küçük modellerin mantığına da bakmanız gerekir. Perceptron bize şunu öğretir: Güçlü yapay zekâ sistemleri büyülü değildir; hepsi belirli temsiller, ağırlıklar, karar fonksiyonları ve optimizasyon süreçleri üzerine inşa edilir. Bu temel görüldüğünde, modern sinir ağları daha az gizemli ve çok daha mühendisçe anlaşılır hâle gelir.